人臉關鍵點 (Facial Landmark)是找出人臉上五官的位置
而目前在應用上人臉關鍵點幾乎都是使用Dlib提供的shape_predictor()方法來偵測,分為兩種:
Dlib提供的方法是在一個已標註好的資料集上做訓練,然後將訓練好的模型給shape_predictor方法當參數使用。
這兩種關鍵點的區別可以看下圖: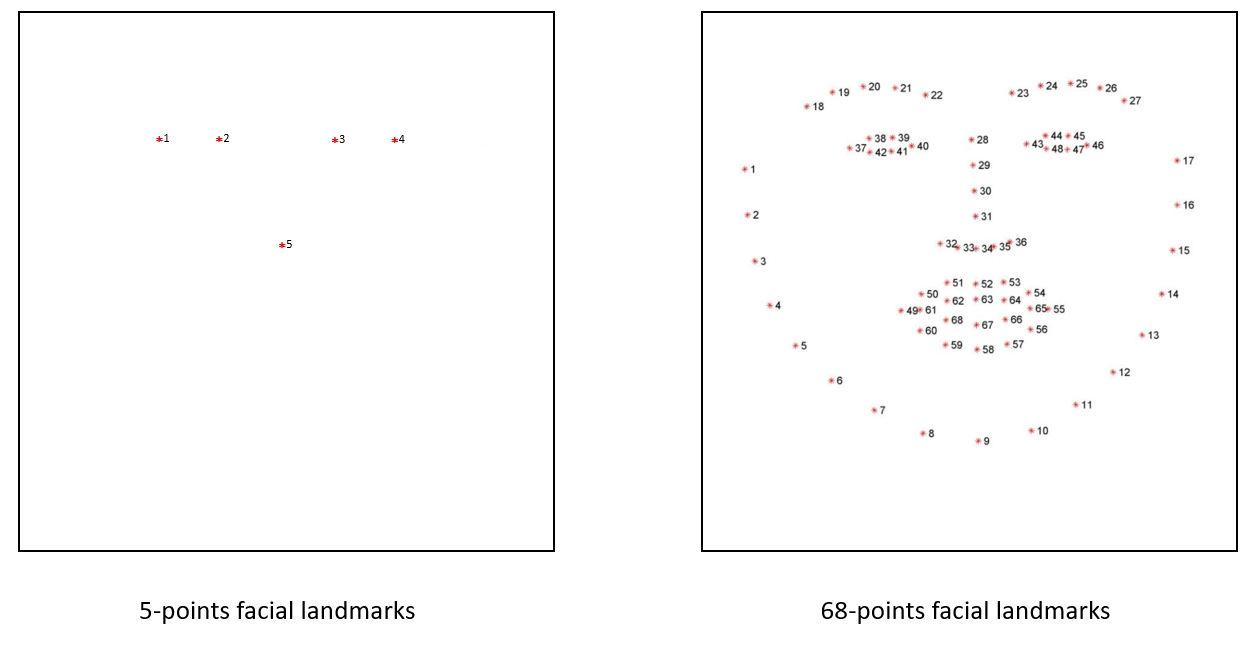
5個關鍵點會使用左眼頭尾、右眼頭尾、鼻頭這五個點來做辨識;
68個關鍵點會使用外輪廓、左眉毛、右眉毛、左眼、右眼、鼻子、嘴巴共68個點來做辨識。
做人臉關鍵點的辨識要做什麼?
這個系列後續應用也會用到這個方法,
所以我們就了解一下要如何使用吧!
facial_landmark目錄dlib_shape_predictor.py
import ntpath
import sys
# resolve module import error in PyCharm
sys.path.append(ntpath.dirname(ntpath.dirname(ntpath.abspath(__file__))))
import argparse
import os
import time
from bz2 import decompress
from urllib.request import urlretrieve
import cv2
import dlib
from imutils import face_utils
from imutils.video import WebcamVideoStream
# 注意這裡我們用的是dlib: MMOD的方法來偵測人臉;你可以試著換dlib: HOG + SVM方法看看結果
from face_detection.dlib_mmod import detect
def download(type):
if type == 5:
model_url = f"http://dlib.net/files/shape_predictor_5_face_landmarks.dat.bz2"
model_name = "shape_predictor_5_face_landmarks.dat"
else:
model_url = f"https://github.com/davisking/dlib-models/raw/master/shape_predictor_68_face_landmarks_GTX.dat.bz2"
model_name = "shape_predictor_68_face_landmarks_GTX.dat"
if not os.path.exists(model_name):
urlretrieve(model_url, model_name + ".bz2")
with open(model_name, "wb") as new_file, open(model_name + ".bz2", "rb") as file:
data = decompress(file.read())
new_file.write(data)
os.remove(model_name + ".bz2")
return model_name
def main():
# 初始化arguments
ap = argparse.ArgumentParser()
# 預設使用5-points的關鍵點方法,可以改參數使用68-points
ap.add_argument("-t", "--type", type=int, default=5, choices=[5, 68],
help="the shape predictor type for prediction")
args = vars(ap.parse_args())
# 下載模型相關檔案
model_name = download(args["type"])
# 初始化關鍵點偵測模型
predictor = dlib.shape_predictor(model_name)
# 啟動WebCam
vs = WebcamVideoStream().start()
time.sleep(2.0)
while True:
frame = vs.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
rects = detect(frame, return_ori_result=True)
for rect in rects:
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
for (s0, s1) in shape:
cv2.circle(frame, (s0, s1), 1, (0, 0, 255), -1)
# 另一種visualize人臉關鍵點結果的方法
# frame = face_utils.visualize_facial_landmarks(frame, shape)
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
# 清除用不到的物件
cv2.destroyAllWindows()
vs.stop()
if __name__ == '__main__':
main()
python facial_landmark/dlib_shape_predictor.py使用預設5-points,或是帶參數-t 68改成使用68-points方法:5個關鍵點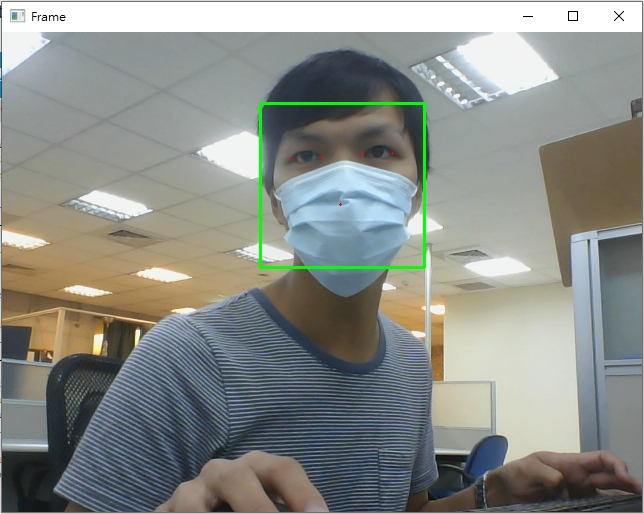
68個關鍵點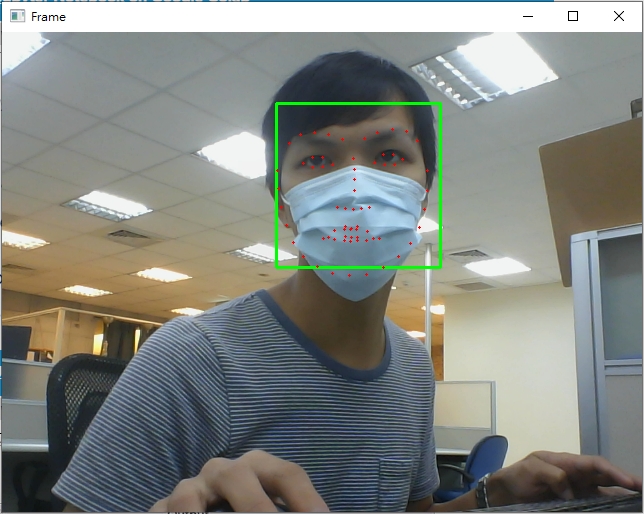
你也可以將程式碼第72行註解取消,用另一種方式觀看關鍵點辨識結果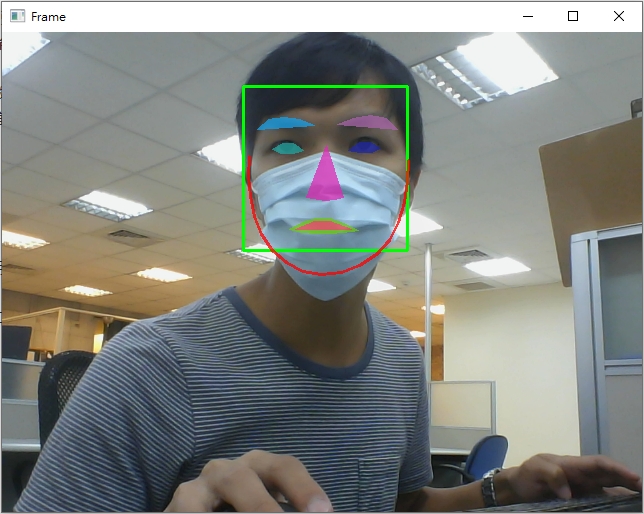
要做人臉關鍵點辨識,
第一步驟一定要先偵測人臉,
而本文使用Dlib: MMOD的臉部偵測方法 (為了戴口罩也能夠偵測出臉部),
但如果臉部只剩下側面臉,
Dlib的臉部偵測效果就不是很好,當然也就沒辦法做人臉關鍵點辨識。
下一篇文章我們將使用另一個也很常用來做人臉關鍵點辨識的模型 - MTCNN。
Today's Portal

